Llama
Llama overview
TL;DR(中文)
LLaMA是 Meta 发布的一组foundation model(7B–65B),以“更充分的数据训练 + 高效训练策略”在同等推理预算下取得了很强的 baseline。- 做产品落地时,通常会优先选 “instruction-tuned / chat-tuned” 的变体;
base model更适合做继续预训练、domain adaptation 或作为研究基座。 - Prompt 层面:给
base model更需要把 output format、style 和 constraints 写得更显式;对事实任务建议接RAG并要求 evidence。 - 评估时不要只看单一 benchmark:用你的真实任务分布做
evaluation,关注 robustness(长上下文、噪声、格式、语言混用)。
How to Prompt(中文,code block 保持英文)
对 base model,优先用“明确规则 + 明确格式 + 明确拒答策略”的模板:
You are a helpful assistant for <domain>.
Rules:
- Follow the output format exactly.
- If information is missing, ask clarifying questions.
- If you are not confident, say "Unsure" and explain why.
Task:
<task description>
Output format:
<schema or bullet list>
Self-check rubric(中文)
- 是否明确区分
base modelvs instruction-tuned 的预期差异(follow instructions / verbosity / safety)? - 是否把格式约束写成可验证的 schema(而不是口头描述)?
- 是否针对 hallucination 风险加入了 evidence/abstain 策略?
- 是否用代表性样本做
evaluation,并记录 prompt/model 版本以便回归?
有什么新鲜事?
这篇论文介绍了一组 foundation model,参数范围从 7B 到 65B。
这些模型在可公开获取的数据集上进行了数万亿 token 的训练。
(Hoffman et al. 2022) 的工作表明,在更小的计算预算下,对更多数据进行训练的较小模型可以实现比其较大的模型更好的性能。论文建议用 200B token 训练 10B 的模型。然而,LLaMA 论文发现,即使在 1T token 之后,7B 模型的性能也会继续提高。
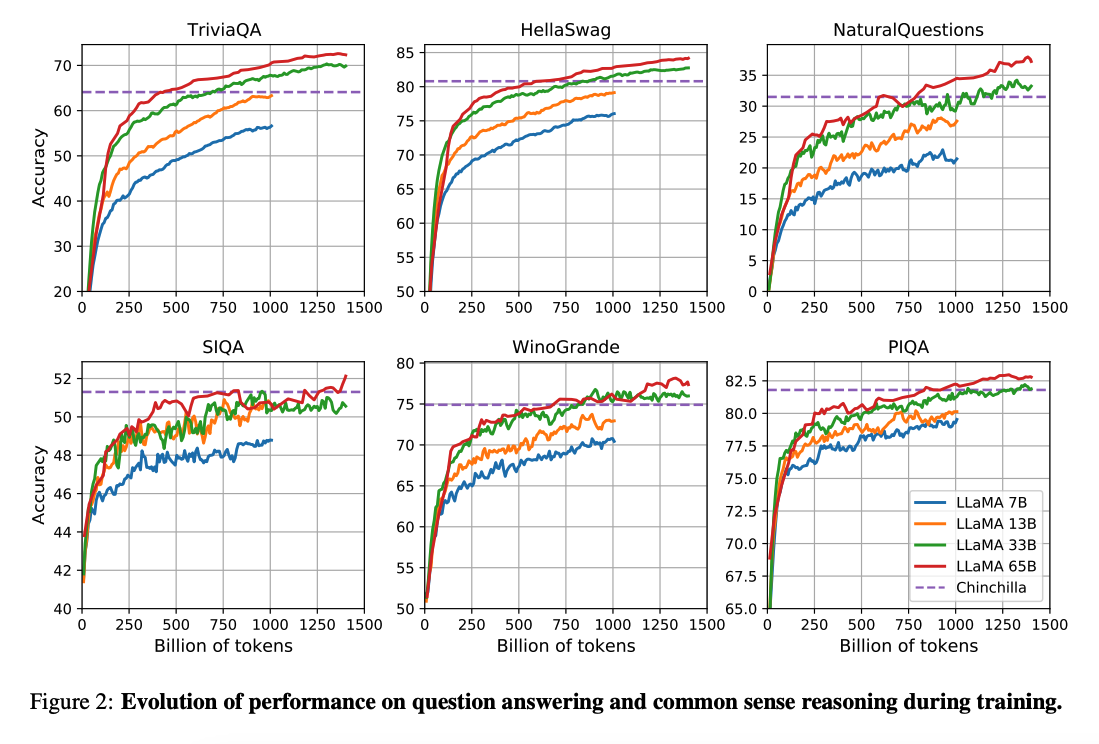
这项工作专注于通过更多的 token 训练模型(LLaMA),使其在不同的推理预算下实现最佳性能。
能力与关键结果
总的来说,尽管 LLaMA-13B 模型比 GPT-3(175B)小 10 倍,但在许多基准测试上的表现仍优于 GPT-3,并且可以在单个 GPU 上运行。LLaMA 65B 与 Chinchilla-70B 和 PaLM-540B 等模型都具有竞争力。
Paper: LLaMA: 开放且高效的基础语言模型
Code: https://github.com/facebookresearch/llama
引用
- Koala: A Dialogue Model for Academic Research (April 2023)
- Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data (April 2023)
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality (March 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (March 2023)
- GPT4All (March 2023)
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge (March 2023)
- Stanford Alpaca (March 2023)